Chapter 10 Data Management
Adapted from the guides of Y. Shorish for CHEM361 by C. Berndsen
The descriptions below are a more general guide to file naming and data management using in the Biochemistry class at JMU. For YASARA specific suggestions see 2.6.1. For those that wish to use this in a class assignment, a suggested assignment can be found here.
10.1 Introduction to the problem
We all have had the problem of saving a file and then having to find that file a year or more later. Once we find where we stored the file and what we named it, we then have to figure out what we did. While this is annoying, the rise of search engines that can search within files has reduced the time spent trying to find a file.
Now imagine you are trying to find a file on someone else’s computer… The challenges would be:
How does this person organize (or not) their files?
What format did they save the data in?
When you find the file, how is the file organized and what does it mean?
The rise of electronic data and open data practices has led to an increase in the need for best practices when recording data. Data files should be easy to read for both humans and computers as well as should be stored and named in a fashion that is easy to follow for the experimenter but also those who might use the data at a later date.
10.2 What are Data?
There are many possible definitions, we will consider any structure, image, number/measurement, or observation as data.
10.3 Effective File naming
Using descriptive file names is a simple way to organize even cluttered data for you and others. At minimum, a good file name conveys the contents of the file, the creator, the version, and creation date. Other useful information can also be included as indicated below, however the key is to be consistent.
10.3.1 Information to consider including in file names
- Project or experiment name or acronym
(e.g. NMR, LakotaInterview, bacteria_resist)
- Researcher name/initials
(e.g. Jones, CB, KTLV)
- Date or date range of experiment
(e.g. YYYYMMDD or YYMMDD)
- Type of data
(e.g. analysis, PCR, live_counts, density)
- Version number of file
(e.g. v1 – this is useful when multiple versions occur on the same day and the date field cannot disambiguate)
- Three-letter file extension for application
(e.g. .docx, .tiff, .pdb. Some operating systems mask this by default, which is unadvisable)
10.3.1.1 Other tips for file naming
A good format for dates is YYYYMMDD (or YYMMDD). This makes sure all your files stay in chronological order, across years.
Don’t make file names longer than ~10 characters; longer names do not work well with all types of software.
Special characters should be avoided, such as: ~! @ # $ % ^ & * ( ) ` ; < > ? , { } ‘ ”
For sequential numbering, use leading zeroes to ensure files sort properly. For example, use “0001, 0002…1001, etc” instead of “1, 2…1001, etc.”
Do not use spaces; they are not recognized by some software. Instead, use underscores (file_name), dashes (file-name), no separation (filename), or camel case (FileName).
10.4 Organizing files
10.4.1 Use sub-folders
Having all the data and analysis in the same folder can be overwhelming, especially on the first glance through a data folder. Creating sub-folders which organize data by experiment type is highly recommended along with further sub-sub folders by date or analysis type or sample name as shown in Figure 10.1. This is only one organization approach, however any method of organization should be accessible to anyone (including future you).
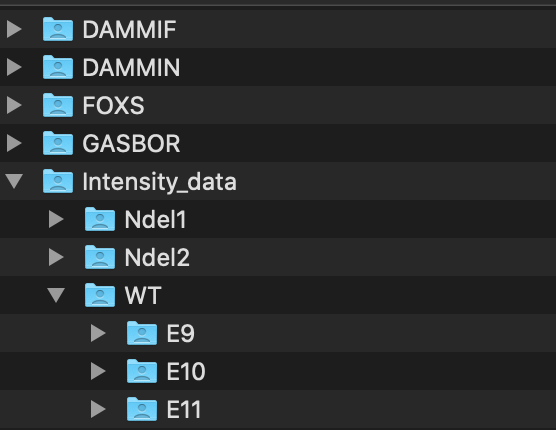
Figure 10.1: One way to organize data in folders
10.4.2 Separate raw data from analysis files
Data are precious and there should be limited or no changes to the raw files. While Excel and other programs make it easy to do plotting and math in the raw data files or to annotate directly on an image file, do not do this. Always create a separate file which is the working copy so that in the event you need to redo the analysis or the file gets corrupted, the raw data are still pristine and ready for new use.
10.5 Data and File Naming Dictionary
Once you have named your file, how do you guide users (sometimes including yourself!) about what your file names and abbreviations mean? This is the function of a data dictionary. This is most often a README.txt file in your directory that explains your naming convention, along with any abbreviations or codes you have used. This could be captured in a Wiki on OSF as well.
Another use of the Data Dictionary is to help users once the file is open. If you have a spreadsheet containing numbers, describe what each column of data show along with any other information needed to read the file. This can include units of numbers, calculations used to derive or transform information, what NA or blanks mean, and any shorthand/abbreviations that might be in the data.
10.6 Data Management Plan
While described last, the data management plan should be one of the first steps in the research process as it lays out the organization of the results. Investing time on the front end of the project to think about how data will be stored and organized will save a lot of time at the end of the project when you have to start interpreting results and drawing conclusions. Trying to find the “good” results in a mess of files is not fun and can lead to lots of unnecessary stress.
An example data management plan for a set of biochemical and computational experiments is shown here.
10.6.1 Data Management Plan questions for students in Biochemistry class:
10.6.1.1 Types of Data
- What data will be generated in the research?
– Is it sequence data? Sensor readings? Observational data? Environmental information? Structural models?- What data types will you be creating or capturing?
– Actual data types here: textual data, image data, tabular, sound, structural…
- How will you collect or create the data?
– Handwritten field notes transcribed to Excel, downloads from instruments, recorded on a device, typed into a text document, written in Python…
- If you will be using existing data, state this and include how you will obtain it.
– Are you pulling from Uniprot, Ensembl, RCSB PDB or other existing data repository?
- How will the data be processed?
– What software will you be using to process the data: Excel, YASARA, R, ATSAS, Coot, PHENIX, Hadoop, ROOT, etc.10.6.1.2 Standards for Data
- Which file formats will you use for your data, and why?
- It is best here to use non-proprietary formats. Example: CSV instead of XLSX, TXT instead of DOCX. If it is necessary to use a proprietary format, explain why.- What form will the metadata describing/documenting your data take?
– This is your data dictionary and the details that you will record therein. - How will you create or capture these details?
– Will this be captured as a data dictionary in a spreadsheet? As a separate file? Will each data set have a separate file, or will you create one ‘master’ README? - What contextual details (metadata) are needed to make the data you capture or collect meaningful?
– Essentially what methods are necessary to reproduce your data.10.6.1.4 Policies for re-use and redistribution
Open access with attribution (CC-BY-4.0) - This is set for this course but for other research would be dependent on standards for the field/discipline.
You can set your re-use policy depending on your feelings about sharing and the type of data involved. There are many types of licenses. See here() for details.
10.6.1.5 Plans for archiving and preservation
- Open Science Framework
- This is set for this course but for other research would be dependent on standards for the field/discipline.
- Your instructor backs all data up to a second cloud-based source and a local hard drive.- Think about how file formats change over time (example. Word doc vs. Word docx). You want to store your data in the most compatible format for use by future users. This is one reason why .csv and .txt are preferred to Microsoft formats. Microsoft may not exist in 20 years!